Stream Boundary
Purpose

The Stream Boundary Controller allows you to split a stream of data into chunks of consecutive streams based on specific conditions. Imagine a continuous stream of data being read from a Kafka topic which you want to turn into individual files. The Stream Boundary Controller allows you to do just that by letting you define the conditions for splitting the stream into chunks. These chunks represent individual streams of their own which can then be subsequently be output to files.
Prerequisites
Before using this Asset, we recommend configuring the Formats you plan to use, first. This will help the Intellisense feature in the mapping configuration to help with the setup.
Configuration
Name & Description
-
Name: Name of the Asset. Spaces are not allowed in the name. -
Description: Enter a description.
The Asset Usage box shows how many times this Asset is used and which parts are referencing it. Click to expand
and then click to follow, if any.
Asset Dependencies
Use this section to add Formats which you plan to use as part of your filtering and routing rules.
Why do I have to add formats here?
Doesn't the system know which Formats I am using?
layline.io automatically understands when you are using Formats as part of your input and output processors and automatically mounts them at runtime.
But when you are referencing Formats which are not used as part of an input or output Processor directly, but rather referenced in
a Javascript Flow Processor or Quickscript, then the system may not be aware that you are using this format within
any of those scripts.
This would result in a runtime error.
To avoid this, you can explicitly mention the Formats you are referencing in your scripts. This ensures, that these Formats will always be mounted at runtime. So it is best practice to add Formats which are referenced in this Asset here.

To add formats click on Add Dependency and select the Format you wish to add as a dependency.
Repeat for any other Format dependency.
Input Ports

This Processor can have one or more input ports from which it receives data to process. It must have at least one input port, however.
A port can have a name and description. Names must exist and be unique within the Processor.
You can add an input port by clicking on Add Port, or remove an input port by clicking on Delete.
You cannot delete the port if it is the last one within the processor.
Output Ports
This Processor can only have one Output Port to send messages on within the Workflow.

A port can have a name and description. A Port Name is mandatory.
You cannot delete the only Output Port.
Boundary Controller
In the Boundary Controller section you define the rules on how to split an incoming stream into multiple streams.
Boundary Controller Type
There are two distinct options on how to do determine the rules for stream splitting:
- Based on Volume ann/or time: The stream will be split based on a preset number of messages or time passed or specific times (e.g. at the full hour).
- Based on stream content: The stream will be split based on the criteria in the content of the stream, e.g. at the appearance of a special type of message or specific content in the message.

Depending on which type you pick for your purposes the configuration differs.
Boundary Controller Type "Duration / Message / Cron"
This Controller Type allow you to split the stream based on
- Duration, or
- Number of Messages (Count), or
- Time
Stream Configuration
Stream Start Mode
Defines when the new stream should be started. You have two options:
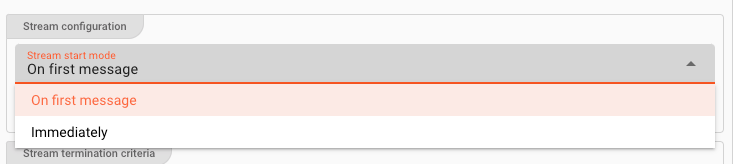
On first message: The outgoing stream will be started, whenever the first message passes through. This option makes the most sense when you for example define that a new stream should be started for each 1.000 messages passing through.Immediately: This setting will start a new stream as soon as the Processor is ready. This setting makes most sense when used in conjunction with time-based stream splitting, e.g. every 60 seconds, or at the full hour, etc.
Name of the split stream
By its nature, the Stream Boundary Controller creates multiple new streams from an incoming message stream. At this point you define the naming convention for the newly created streams:

As you can see from the example above, you can use Macros here.
In this case we chose to include a constant MyStreamName- plus the current date and time in the newly created stream name.
Stream Termination Criteria
In this box you define the criteria upon which the current stream shall be committed and a new stream started (i.e. the splitting criteria).
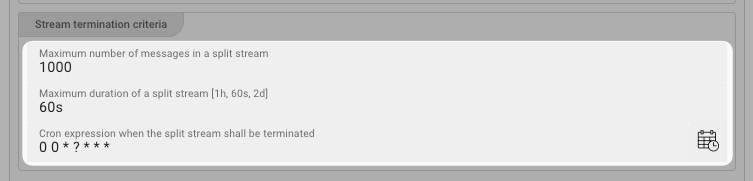
In our example above we have defined the following
-
Max. number of messages in split stream(e.g. 1.000): Create a new stream every 1.000 messages. Note, that if a stream runs shy of 1.000 messages, the newly created stream will never be closed. You should consider using this parameter in conjunction with one of the two following time based parameters. -
Maximum duration of a split stream(e.g. 60s): Start a new stream every 60 seconds from start of new stream. Accepts the following notations:What Unit MILLISECONDS ms, millis, milliseconds MICROSECONDS us, micros, microseconds NANOSECONDS ns, nanos, nanoseconds DAYS d, days HOURS h, hours SECONDS s, seconds MINUTES m, minutes -
Cron expression on when stream shall be terminated(e.g. "0 0 * ? * * *"): Strictly time based condition on when current stream should be closed. Enter a cron term here. Either enter the term yourself using quartz notation, or click the button to the right of the field for assisted entry.
Keep in mind, that each termination condition applies on its own. So in case, you have defined a stream to terminate each 1.000 messages, and have also defined for a stream to be terminated each 60 seconds, then both triggers will apply on their own terms. That is either after 1.0000 OR after 60 seconds.
This behavior can be desired, as it will allow you to split a stream every 60 seconds regardless of whether 1.000 messages have been reached or not. Should you receive more than 1.000 messages per 60 seconds, then the output will always be 1.000 messages per split stream. Should the incoming stream fall below 1.000 messages per second then it will be split after 60 seconds regardless.
Boundary Controller Type "Message Matching"
This Controller Type will allow you to split a stream based on the stream content.
A practical example would be that - within your incoming message stream - you receive certain message types that should signal the beginning of a new stream as well as the end.. In other words, split stream boundaries can be determined based on the stream's content.
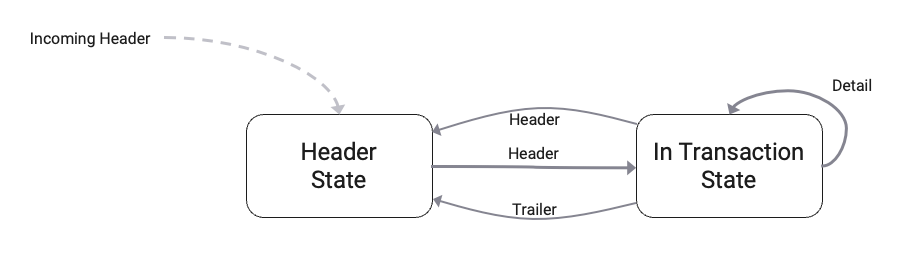
This is comparable to interpreting a data format which has a header, detail and a trailer message. Unlike in file processing the data is received as a continuous stream, however. Imagine you are reading data from a Kafka topic which contains messages in this order, then this Controller will allow you to split this continuous stream into individual streams based on the header and trailer marker messages.
Example Data Stream:
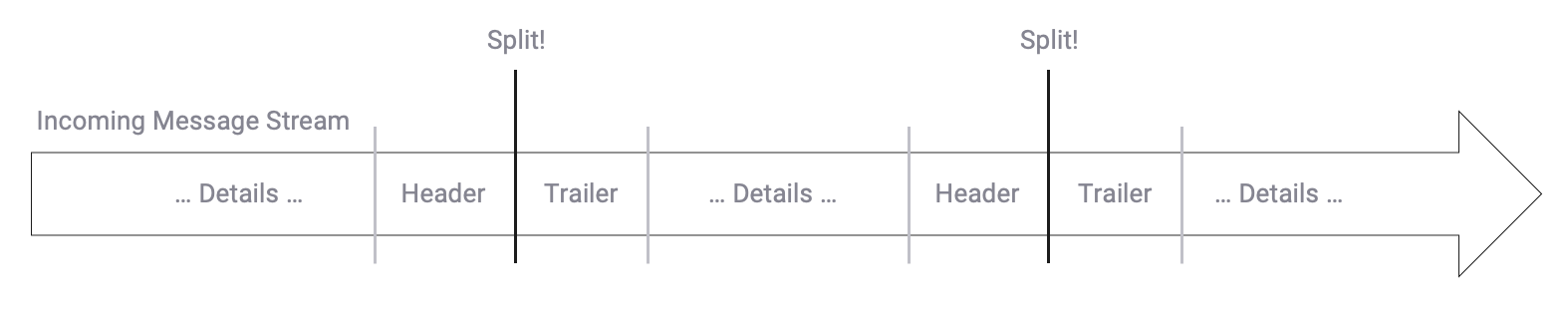
Finite State Machine
Essentially the rules to split a stream of messages into individual streams can be reflected by a Finite State Machine. Let's explain:
In order to split a continuous stream the Controller must know what message to expect so that it can decide
- what to do with each message that "flies by", and
- when to actually split the stream based on definable conditions.
In doing so, the Controller needs to be able to keep track of different states. Taking our example from above we do have the following rules to observe:
- A new stream starts with a message of type
Header. - Subsequent messages must be of type
DetailorTrailer. - Once we receive a
Trailermessage the stream ends. We expect aHeadermessage after that. - If we receive a
Headerdirectly after having received aDetail, it's an error.
So basically we have two states, each one with its own conditions:
- State #1 "Header":
- Waiting for a
Headermessage. - Anything else ignore it.
- Waiting for a
- State #2 "In Transaction":
- Processing
DetailsandTrailermessage. - If we receive a
Header, that's an error.
- Processing
The UI supports you in entering these states and related conditions. We will explain how to do this, using our example:
States
In addition to representing a State, States can also forward messages as output, or inhibit forwarding of messages.
Adding a State
To add a State, click on + ADD STATE.
A State will be automatically inserted in the table below.
We name the State Header.
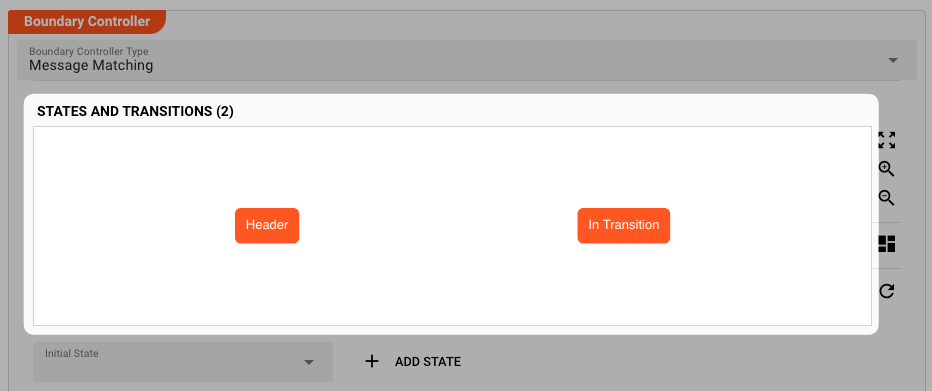
Add another State In Transaction.
You now have two States. The States do not contain any Cases yet.
In the graph above the table, you should be able to see your two States:
Add as many states as your model requires. You can also add or remove States later.
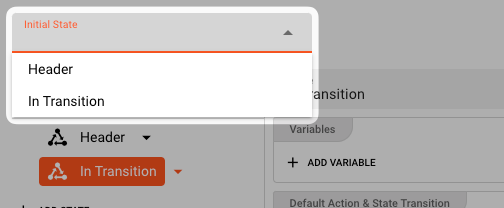
Setting the Initial State
A State Machine must start somewhere. It's the same with this State Machine which is why you must set the initial state of the state machine here:
State Variables
The current version of the UI, already allows you to define State Variables. State Variables serve the purpose of passing values from one State to another.
As an example you could pass a field StreamId from the Header message in the Header State, to the In Transaction State.
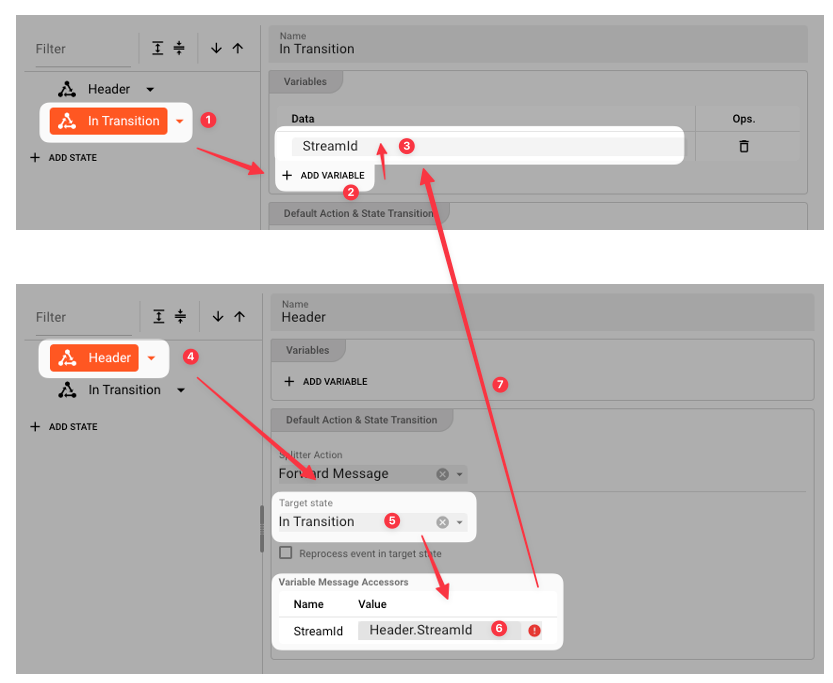
In that State you could then use the value, e.g. to check whether the data you are processing in the In Transaction State stems from the same StreamId by comparing contained StreamId information with that from the variable.
This feature is currently not supported. You can therefore define variables at this stage, but not use them.
Cases
Cases are defined within States.
Cases define the conditions upon which
- messages are forwarded / inhibited, and
- State-transitions are performed.
You may have noticed, that there is always a default Case which you can configure on State level. It is triggered when nothing else fires.
By default, it will forward the current message.
To further our example, let's add a Case which transitions state to the In Transaction state when a Header type message is encountered, and also forwards the Header message downstream.
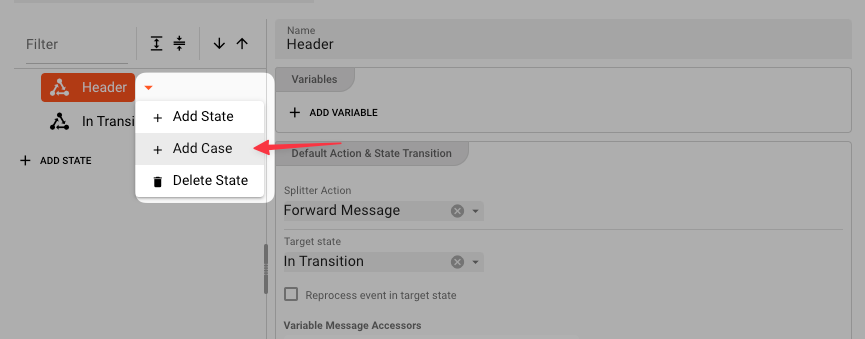
We now have a new Case for which we can enter the details:
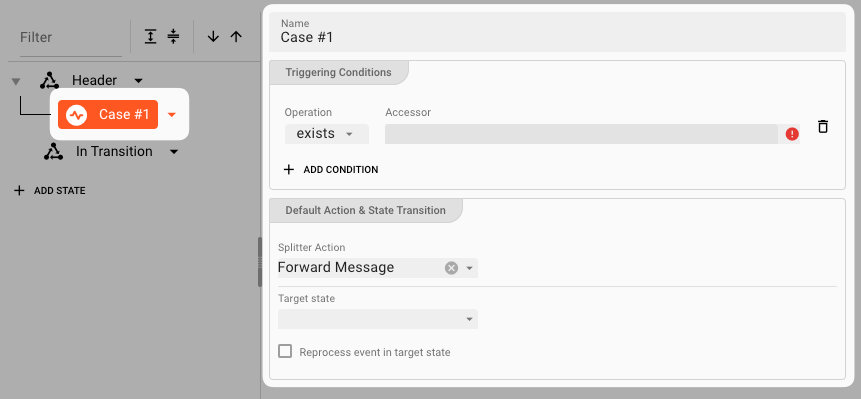
A Case is split between
- "Case and related triggering conditions" on the left (-> WHEN to do things), and
- "Action & State Transition" on the right (-> WHAT to do)
Conditions
Conditions define when a passing message within the current State should trigger an Action.
Currently two operations are supported:
exists: Looks for a message data dictionary structure to exist within the message.equals: Looks for specific content to exist in the message.
Multiple conditions all need to match for the Case to fire.
Examples Conditions:
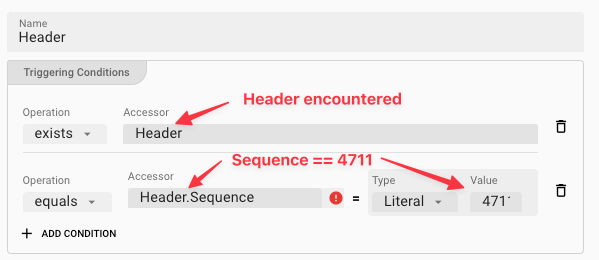
For the purpose of our example we only need the first condition.
Action & State Transition
Actions and State Transition define what should happen if the previously defined conditions apply. You basically define
- Splitter Action: What should happen with the message.
- Target State: Whether a State Transition should be triggered and where to.
Splitter Action options:
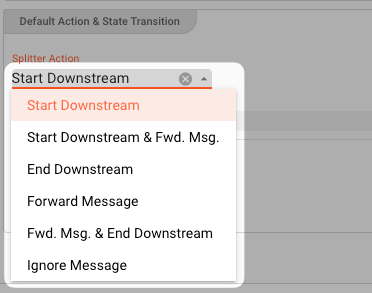
| Splitter Action | Effect | Other options | |
|---|---|---|---|
| Start Downstream | Start a new stream. The original message is NOT forwarded. | - Stream Name: Name of the newly created stream.You can use Macros here. Example: ${msg:Header.Name} | |
| Start Downstream & Forward Message | Same as Start Downstream, but the original message IS forwarded. | Same as above. | |
| End Downstream | Ends the current downstream. This is equivalent to a "split" of the incoming stream. The current message is NOT forwarded. Now a new stream can be started based on another Case. | - Stream Result: Pick either Failure or Ok depending on how you want to value the outcome. Pick Failure for example if the value encountered is not what was expected.- Reason text: Enter a text here which you want to attach to the status of this message. This is especially helpful in case you defined Failure as a result. You can then see the message you enter here as part of the failure status in the log.- Trigger Upstream Savepoint: Check this to make sure that the upstream source which is delivering the messages is notified that it should be trigger a savepoint, i.e. memorize the position. Should the system try to reprocess data, it will only be reprocessed from that point forward. The delivering source, must support savepoints (e.g. Kafka). | |
| Forward Message | Just forward the message downstream. | - | |
| Forward Message & End Downstream | Same as End Downstream, but also forwards the message downstream. | - | |
| Ignore Message | Do nothing with the message. It will be ignored and NOT sent downstream. | - |
Forwarding a message in this context means that the message is forwarded for downstream processing. If you select an option which does not forward the message, then the original message will be destroyed and will not be forwarded.
Target State:

The Target State defines which State should be assumed if the conditions of this Case match.
You can pick of one of the existing States which you have defined.
Reprocess event in target state
As we have learned, in the Controller Type "Message Matching", a message can trigger a State change. You may want to reprocess this message in the new state. In this case, check this box.

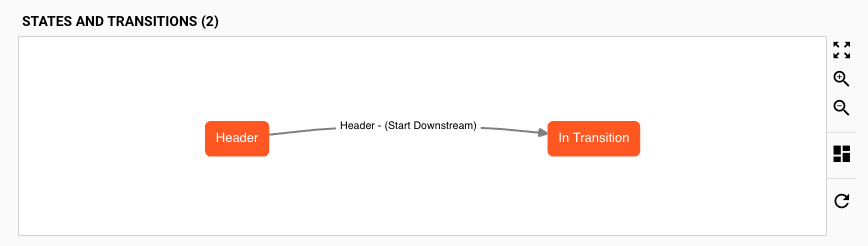
Revisiting the State Graph at the top of the table, this now reflects the state transition condition which you have just configured:
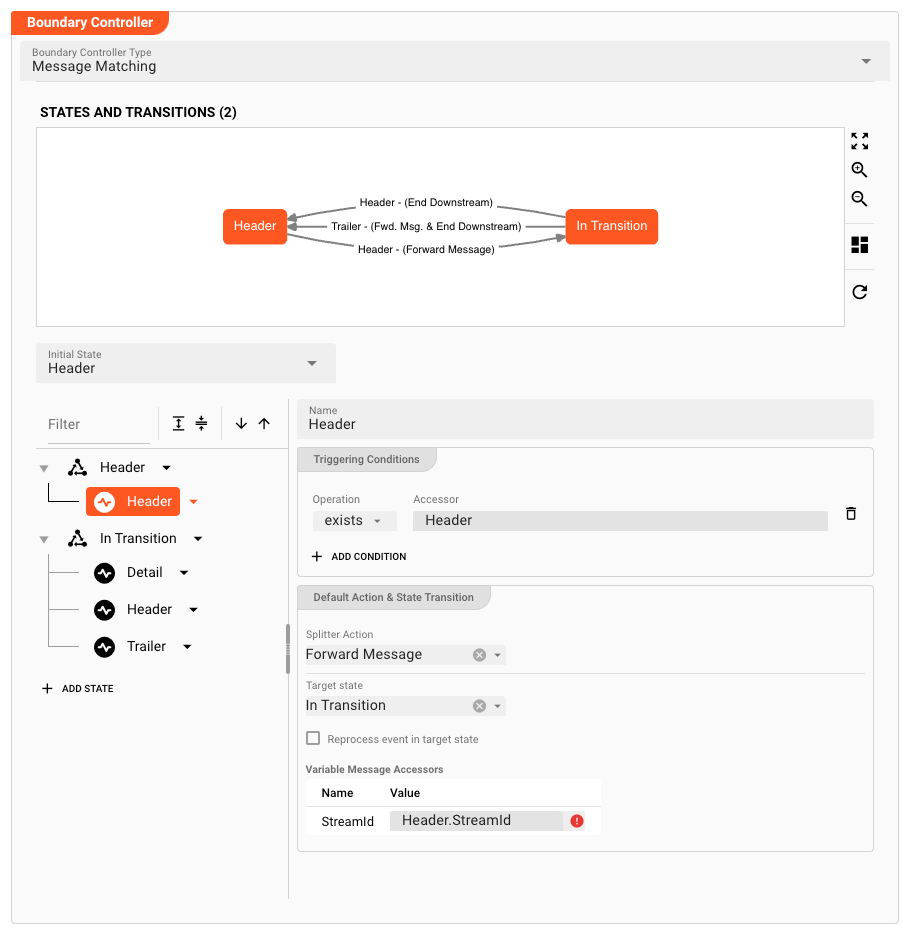
Complete Example Configuration
If we complete all settings based on our example, we come up with the following:
Failure Handling
Processing within a Flow Processor like this one can fail for various reasons. In this section you can define how the system should behave in case of such problems.
Failure Types
Four types of failures are observable:
| # | Failure observables / Reaction | Ignore | Retry Event/Message | Retry Stream | Rollback Stream |
|---|---|---|---|---|---|
| 1 | Stream start failure handlingA problem occurred in this Asset when starting a new stream. | ✔ | ✔ | ✔ | ✔ |
| 2 | Stream end failure handlingA problem occurred in this Asset when ending a stream. | ✔ | ✔ | ✔ | ✔ |
| 3 | Message failure handlingA problem occurred when handling a specific message in this Asset. | ✔ | ✔ | ✔ | ✔ |
| 4 | Rollback commit failure handlingA problem occurred during system issued rollback or commit procedure. | ✔ | ✔ | ✔ | ✔ |
Failure Type Reactions
Each of these failure types can be responded to with four different reactions:
Ignore
Don't do anything.
Rollback Stream
Rollback the complete stream. In the case of batch/file processing for example the complete file (which represents the stream) will be rolled back and put into error.
A rollback signal will be issued to all participating Workflow Processors. Each Processor needs to ensure itself how to deal with a rollback. A Javascript Flow Processor, for example, which directly interacts with a database will have to react to a rollback signal:
export function onRollback() {
if (connection) {
try {
connection.rollbackTransaction();
connection.closeConnection();
} catch (err) {
} finally {
connection = null;
}
}
}
Retry Stream
Don't simply give up. Try to process the whole stream again. This option allows you to define how often and in what intervals the retries should be performed.
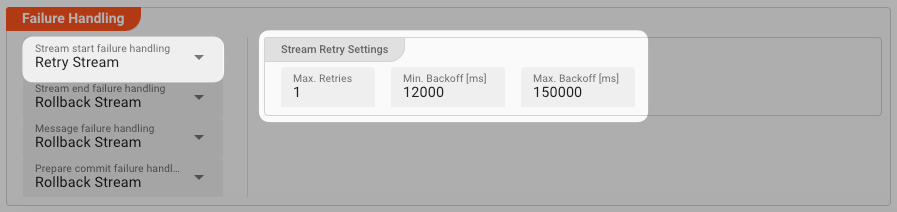
Stream Retry Settings
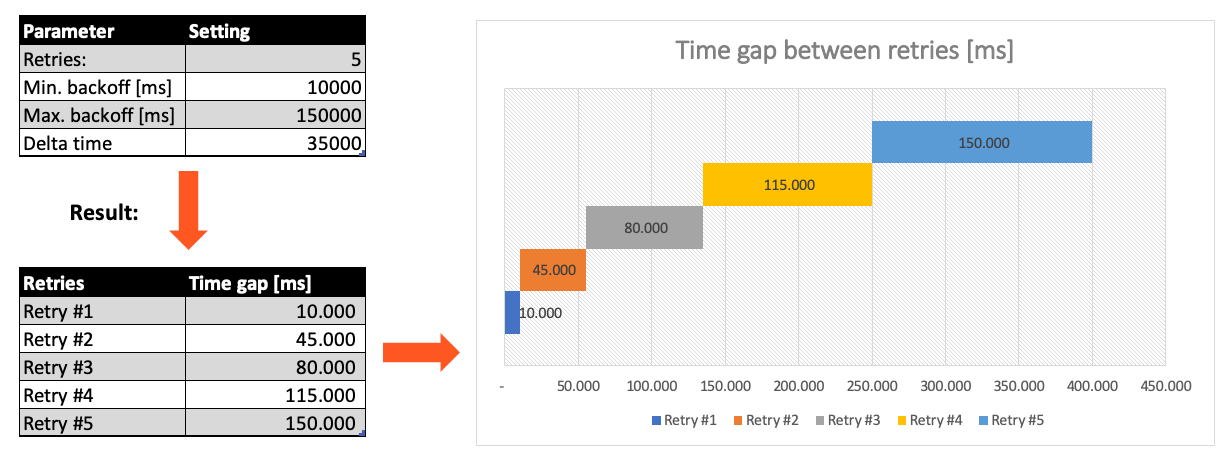
Max. Retries: The number of retries which should be performed. For example "5".Min. Backoff [ms]: Wait at least x milliseconds between each retry. For example "12000" (12 seconds).Max. Backoff [ms]: Wait at max x milliseconds between each retry. For example "150000" (150 seconds).
Based on these parameters, the system will try to balance the defined number of retries within the time boundaries of min. backoff and max. backoff. Taken the example numbers from above, the five retries would happen in this timespan:
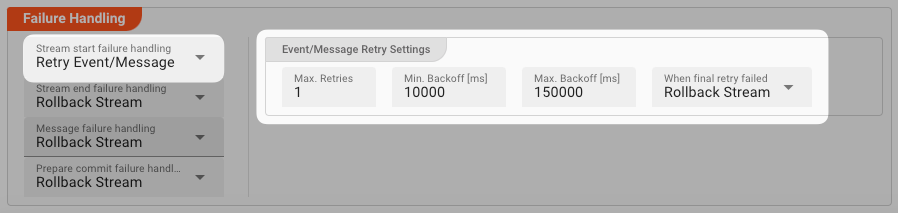
Retry Event/Message
Pick this reaction if you want to retry processing the current message. As is the case with the Retry Stream reaction you can define how often and in what intervals the retries should be performed.
The settings are the same as with the Retry Stream reaction. So please refer to this.
There is one additional setting, however, which is When final retry failed.
You here have the option to decide what to do if the message cannot be processed, even after the final retry:
-
Ignore: Don't do anything. -
Rollback Stream: Fallback to rolling back the whole stream. -
Retry Stream: Retry the whole stream once again. If you pick this option, then you can again define all relevant Retry Stream parameters.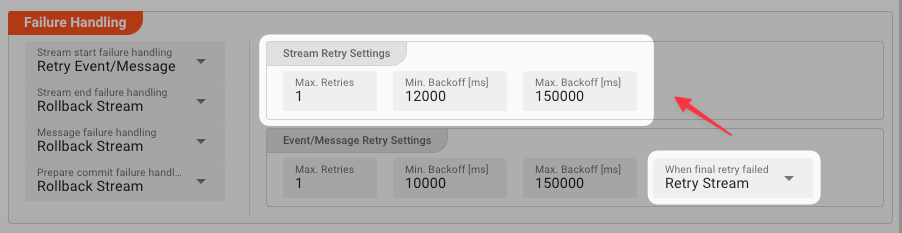
A Workflow has one Input Processor which is responsible for reading data from a Source. Sources are for example files, databases, or message queues.
The settings for Retry Event/Message and Retry Stream only work for specific Source Types which a Workflow uses.
These are:
Processing within a Flow Processor like this one can fail for various reasons.
In this section you can define how the system should behave in case of such problems.
Please note, that the creation of the online documentation is Work-In-Progress. It is constantly being updated. should you have questions or suggestions, please don't hesitate to contact us at support@layline.io .