Input Kafka
Purpose
Defines input parameters to ingest data from a Kafka topic.
This Asset is used within a Workflow definition.
")
Prerequisites
You need: A defined Format
A Kafka Sink:
Configuration
Name & Description
")
Name : Name of the Asset. Spaces are not allowed in the name.
Description : Enter a description.
The Asset Usage box shows how many times this Asset is used and which parts are referencing it. Click to expand and then click to follow, if any.
Output Ports
This Processor can have one-to-many Output Ports to send messages on within the Workflow.
A port can have a name and description. Names must exist and be unique within the processor.
Termination Settings
Using termination settings you can control how layline.io should behave upon shutdown of a Workflow that this Asset is part of. A Workflow shutdown at most goes through three phases:
- Signalling shutdown: layline.io signals inputs that it wants to shut down.
- Signalling abort: In case the shutdown was not confirmed, layline.io sends an abort request.
- If the abort was not confirmed, layline.io terminates the input without further wait.
")
-
Shutdown grace period [ms]: Time to wait for the input processor to gracefully confirm shutdown once a shutdown request has been received. -
Abort grace period [ms]: In case the shutdown signal was not confirmed in due time, an abort request will be issued. If the abort is not confirmed in the configured time interval, a hard termination will be issued. The abort timeout is consecutive to the shutdown timeout.
Format
Data read from a Kafka topic must be read in a format which must have been previously defined by you.
")
If you have defined such a format, then you can select it from the list of available formats by clicking on the button next to the field (1).
Kafka Source
You need to assign a Kafka Source. The Source defines which topics can be read from. The Source must have been previously defined.
")
Select the Sink by clicking on the button next to the field (1).
Kafka Settings
In the Kafka Settings section, you define how you want to read data from Kafka topic(s).
Consumer Group and Polling
")
-
Group ID: TheGroup IDreflects Kafka's Consumer Group ID. A unique string that identifies the consumer group this consumer belongs to. This property is required if the consumer uses either Kafka's group management functionality or the Kafka-based offset management strategy. If you don't know what this is, please consult Kafka's documentation. -
Max. poll records: Number of records to read from a Kafka topic in one go. E.g. a value of500means that messages are read in chunks of 500 from the configured Kafka topic(s). This is equivalent to Kafka's max.poll.records parameter. -
Max. poll interval [ms]: Timeout for in-between polling intervals. E.g. a value of300000means that Kafka will wait for 5 minutes for the client to return and ask for more data before it. This places an upper bound on the amount of time that the consumer can be idle before fetching more records. If the next polling is not invoked before expiration of this timeout, then the consumer is considered failed and the group will rebalance in order to reassign the partitions to another member. This is equivalent to Kafka's max.poll.interval.ms parameter.
Example:
Let's assume a Kafka topic is distributed across two partitions P1 and P2, and you are running two Workflow instances W1 and W2 with the same Kafka input processor as configured above.
In this case Kafka will see two clients both accessing the Kafka topic with the same Consumer Group ID XYZ.
Kafka will assign one partition P1 to Workflow W1 and partition P2 to Workfkow W2. Each time a client asks for data, Kafka will provide messages in chunks of 500.
Should Workflow instance W2 not return and ask for more data within 5 minutes (300000 ms), the respective Workflow instance will be considered failed and Kafka will rebalance the partitions to now be
both read by Workflow W1.
Auto Offset Reset Strategy
")
This allows you to define what to do when there is no initial offset in Kafka or if the current offset does not exist any more on the server (e.g. because that data has been deleted):
Read earliest message: Automatically reset the offset to the earliest offset.Read latest message: Automatically reset the offset to the latest offset.Do not start up: Don't start and report an error if no previous offset is found for the consumer's group.
You can read more about this in the Kafka Documentation here.
Topics
Define one or more topics that this input processor should read from. If you have defined a consumer group then the topics which you define here will be accessed with the same consumer group. You can use ${...} macros to expand variables defined in environment variables.
")
Commit Mode
The commit mode defines how the system should commit successful reads and processing back to Kafka. There are four options:
No Commit
")
Processed messages will not be committed back to Kafka. This is likely not desired as it is imperative to have control over what messages were suceessfully processed in order to avoid duplicate processing as well as ensure that all messages are being processed. The option is included for completeness nonetheless.
Auto
In the Auto Commit Mode, messages are being committed in frequent time intervals.
I.e. regardless of processing status, the offset of messages which have been read is being committed every 5000ms (example).
")
This is equivalent to Kafka's auto commit feature.
SavePoint
")
The SavePoint commit mode has no equivalent in Kafka. This actually represents "no commit, until explicit commit". There are mechanisms within layline.io which allow to trigger a so called "upstream savepoint" based on certain conditions. If such a savepoint is triggered, this is then propagated back up. In this case the then current offset will be committed back to Kafka.
An example can be found in the Stream Boundary Controller Asset where a savepoint can be triggered upon configurable conditions. So if you have a Stream Boundary Controller in you Workflow, then a savepoint can be triggered from within that Processor.
Example: Stream Boundary Controller SavePoint trigger
")
Message
The Message Mode commits the read offset back to Kafka based on time and number of messages.
")
-
Maximum number of messages in a commit batch: As the name implies, a commit is issued to Kafka when the number of read messages has reached the configured threshold. In the example this would be after1000messages an offset commit is issued to Kafka. A configuredMaximum commit interval in secondsmay supersede the duration until a commit is issued. -
Maximum commit interval in seconds: This is the maximum number of seconds to wait before committing read offsets back to Kafka. In the example this would be after10seconds. Should the number of messages read be smaller than what is configured inMaximum number of messages in a commit batchthe offset will still be committed after teh configured time interval. -
Maximum number of in-flight commit messsages: Number of issued commit messages which can be open at any time. If the number is100then in our example this implies that a maximum number of 1000 x 100 = 100.000 messages can be uncommitted and waiting for commit at any time. -
Delivery of commits to Kafka: If set toWait for acknowledgethen the system will wait for commits to be confirmed (safe). If set toSend and forgetthe system will assume that issued commit requests have been successfully committed (unsafe).
Failure Handling
Processing within an Input Processor like this one can fail. In this section, you can define how the system should behave in case of problems.
Failure Types
One type of failure is observable:
| # | Failure observables / Reaction | Ignore | Retry Event/Message | Retry Stream | Rollback Stream |
|---|---|---|---|---|---|
| 1 | Source failure handlingA problem occurred with the Source of the messsages. | ✔ | ✔ |
Failure Type Reactions
The following two failure reactions are supported.
Rollback Stream
Rollback the complete stream. In the case of batch/file processing for example the complete file (which represents the stream) will be rolled back and put into error. This is the default behavior.
A rollback signal will be issued to all participating Workflow Processors. Each Processor needs to ensure itself how to deal with a rollback. A Javascript Flow Processor, for example, which directly interacts with a database will have to react to a rollback signal:
function onRollback() {
if (connection) {
try {
connection.rollbackTransaction();
connection.closeConnection();
} catch (err) {
} finally {
connection = null;
}
}
}
Retry Stream
Don't simply give up. Try to process the whole stream again. This option allows you to define how often and in what intervals the retries should be performed.

Stream Retry Settings
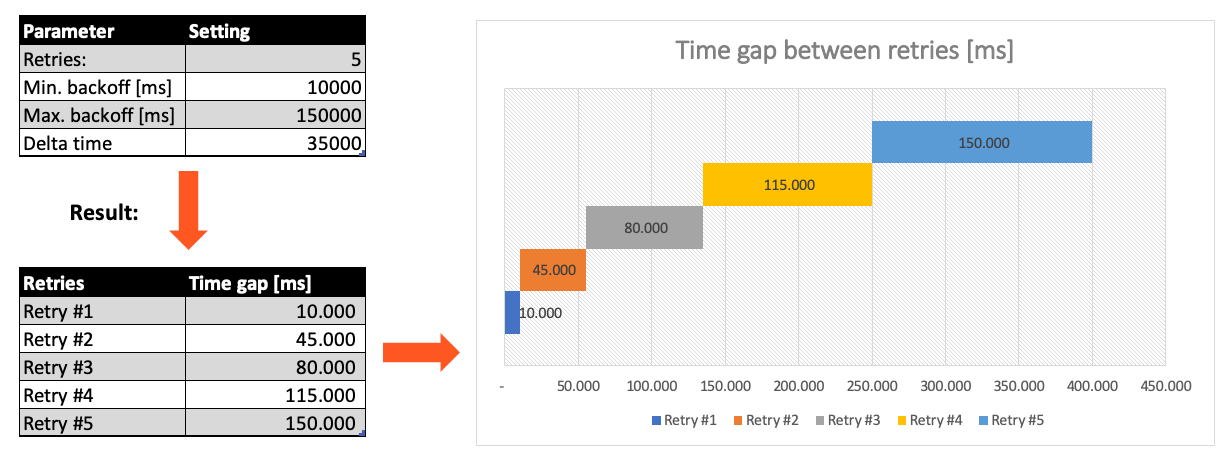
Max. Retries: The number of retries which should be performed. For example "5".Min. Backoff [ms]: Wait at least x milliseconds between each retry. For example "12000" (12 seconds).Max. Backoff [ms]: Wait at max x milliseconds between each retry. For example "150000" (150 seconds).
Based on these parameters, the system will try to balance the defined number of retries within the time boundaries of min. backoff and max. backoff.
Taken the example numbers from above, the five retries would happen in this timespan:
Related Topics
Internal
External
- Kafka's Consumer Group ID
- Kafka max.poll.records
- Kafka max.poll.interval.ms
- Kafka auto.offset.reset
- Kafka enable.auto.commit
Please note, that the creation of the online documentation is Work-In-Progress. It is constantly being updated. should you have questions or suggestions, please don't hesitate to contact us at support@layline.io .